

はじめに
歌詞分析をやってみたい!が、肝心の知識はというと、私はPython入門のfor文をイマイチ理解できずに躓いたまま放置しているし、何よりもプログラミングはミリしらである。
それでも、やりたい。
無知且つ強欲なオタクは、使えるものをすべて使って成し遂げようと覚悟を決めた。
これはそんな私がChatGPTに教えてもらいながら大好きなバンドであるTHE BACK HORNの歌詞分析を行った記録である。
今回の取り組みはミリしら無知無学の人間がWordCloudによる可視化のみを目的に行った(=結果のみを重視した)ことであるゆえ、憚らずに言うと、自身のスキルアップやコードの的確さには重きをおいていない。悪しからず何卒ご容赦いただきたい。
作業環境
- 歌詞データの取得・・・UiPath StudioX(バージョン2022.10.8)
- 歌詞分析・・・・・・・GoogleColaboratory
歌詞分析の流れ
歌詞分析の流れは以下のとおりである。
- STEP1歌詞を抽出し、csvを作成
今回は「歌ネット」から歌詞データを取得する。
- STEP2歌詞を単語単位に分割
Janomeを用いて歌詞を単語ごとに分ける。
- STEP3単語を可視化
可視化にはWordCloudを利用。
当初はすべてPythonで実施しようと思い、歌詞データ抽出も、WordCloudによる可視化も、諸賢が記したコードを解読しながら実装を試みた。
が、いかんせん当方には応用力など皆無である。記されたコードを応用できるなどと考えている時点で調子に乗りすぎている。
というわけで、潔く作業を分けることにした。
具体的に行ったのは、歌詞データの取得にはRPAを使用すること、歌詞分析にはChatGPTを投入することである。
歌詞の取得
歌詞データを取得するためにはWEBスクレイピングを行うことが一般的な手法である。WEBスクレイピングとは、端的に言えばWEBサイトなどから多くのデータを抽出することである。
スクレイピング自体を禁止しているサイトもあれば、そもそもスクレイピングはサーバに負荷をかけることが否めないので、実施するにあたり、各サイトの利用規約を事前によく理解する必要がある。
なお、スクレイピングの詳細や留意事項はこちらのサイトで詳しく解説されているので、必要に応じて各自確認していただきたい。
Pythonで実行することを放棄したので、残された手段は自ずと限られる。よって今回は、ノンプログラマー向けのソフトであるUiPath StudioXを用いて歌詞データを取得することにした。
StudioXの詳しい説明は割愛するとして、ここでは、当初想定していた方法ではテキストを取得できなかったことも含め、歌詞取得の自動化について手順を簡単に記す。
RPAの全体イメージ
- STEP1表抽出(繰り返し)
表形式のデータとしてそれぞれの歌詞を取得する。
- STEP2複数のExcelを一つにまとめる
見出しごとに出力されたデータ(複数ファイル)を一つのファイルにまとめる。
- STEP3csv変換
Excelをcsv(csv utf-8)に変換する。
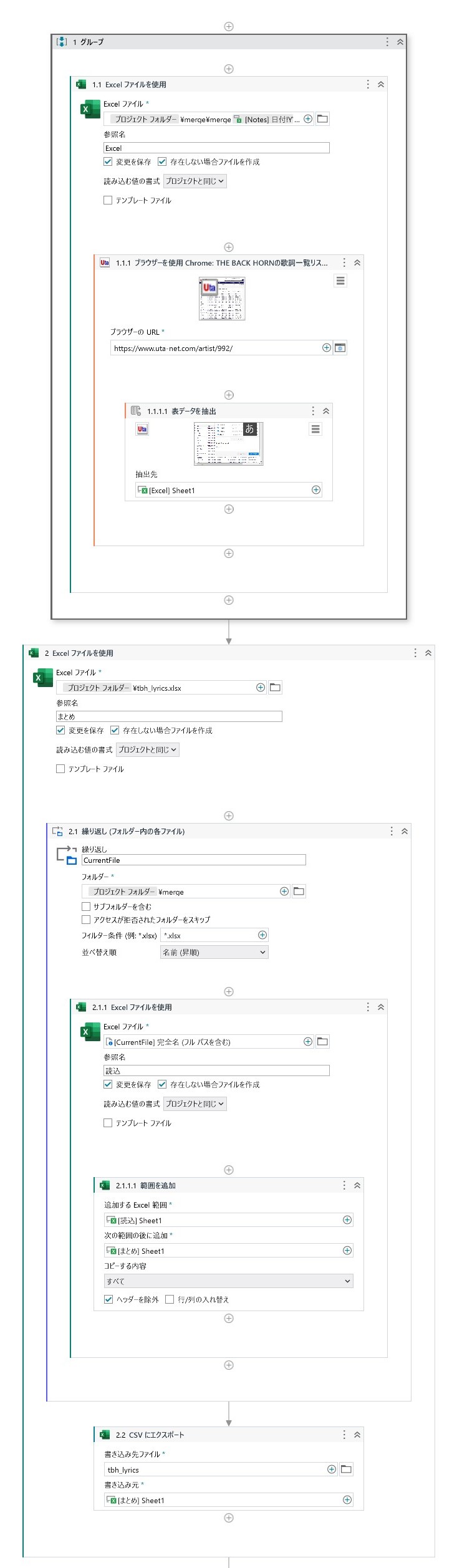
表抽出
StudioXには「表抽出」という機能がある。これを用いれば、表形式データを一括で取得することができる(参考ページ)。言うなればWEBスクレイピングに似た機能である。

しかし、該当のサイトには、30曲ごとに見出しが挟まれている。そのため、一度に抽出できるのは、見出しと見出しの間にあるデータのみに限られてしまうことが発覚する。

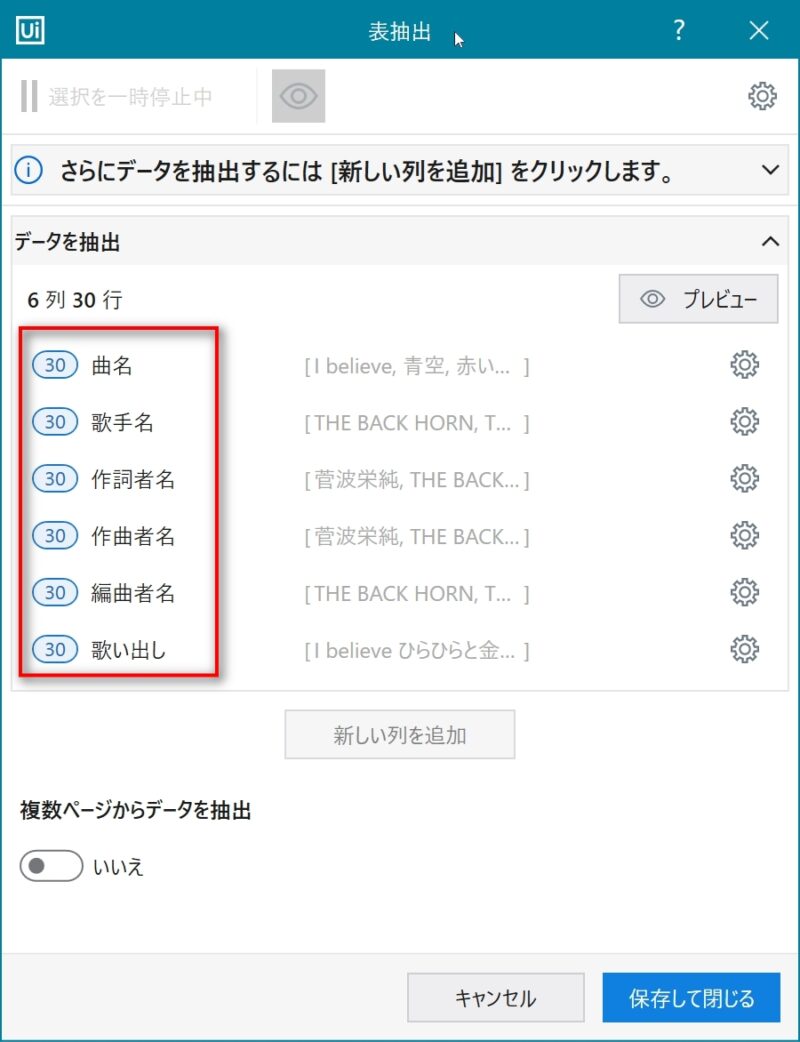
背に腹は代えられないので、30曲ごとに見出しを指定しなおし、取得した内容をExcelに都度出力することにした。
完全に自動化できたわけではないが、一曲一曲を手作業で抽出することを思えば十分な効率化である。
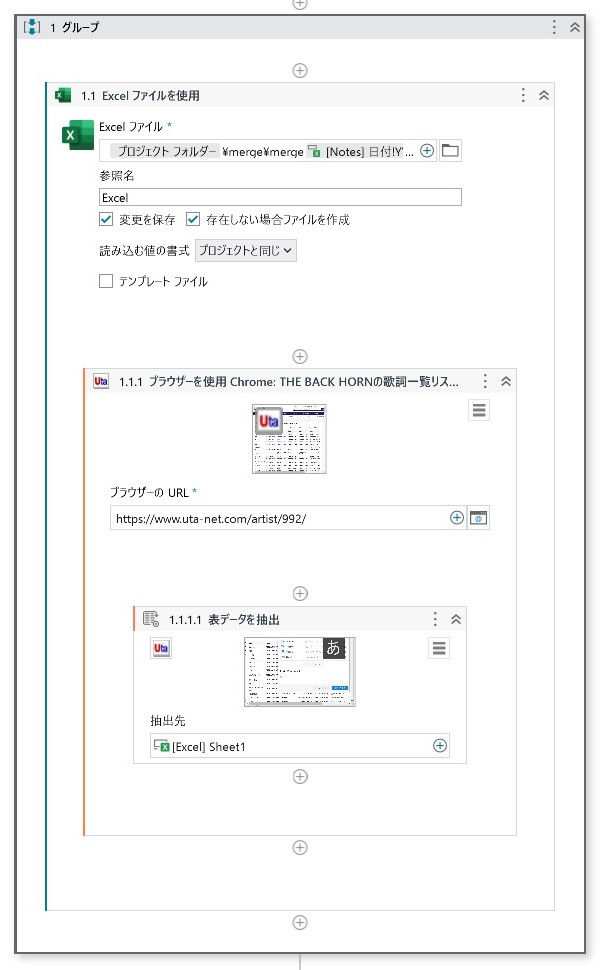
見出しが一つであれば、セットするのは「表抽出」アクティビティのみで済む作業である。しかしながら今回は、Excelが複数出力されることになるため、「Excelファイルを使用する」アクティビティのなかに「表抽出」を配置した。
歌詞をすべて取得できたら、これらのExcelを1つにまとめる作業に移る。
複数のExcelを1つにまとめ、csvを作成する
繰り返し処理で複数あるExcelを1つのファイルにまとめる。
処理内容は、まとめ用のExcelに、それぞれ取得したデータをファイルがある分繰り返して貼り付ける、というものである。
抽出したデータをすべて貼り付けるため、ヘッダーである見出し部分は一律除外した。そのため、まとめ用のExcelにも見出しはないので、手間にはなるが、後付けでまとめ用のExcelに見出しを追加した。
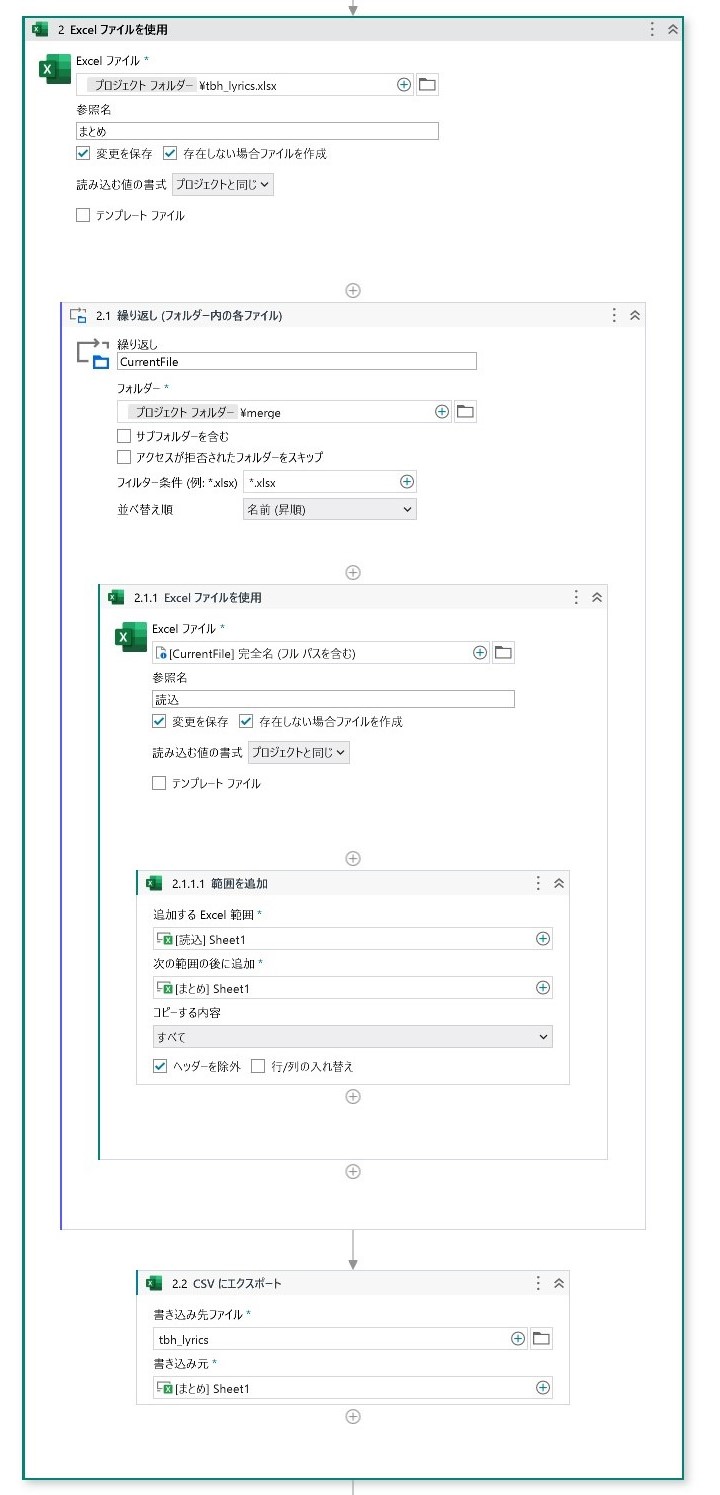
そのほかにも、カバー曲や空白部部、不要なデータを手作業で削除する。前処理が完了したら、csvファイルの形式を「CSV UTF-8」に変更したうえで、Google Driveの任意の場所に保管する。
※StudioXでcsv変換を行うと、「CSV(コンマ区切り)」として保存されるらしい。これでは、Python側でエラーが起きたため、ファイル形式を手動で「CSV UTF-8」に修正した。
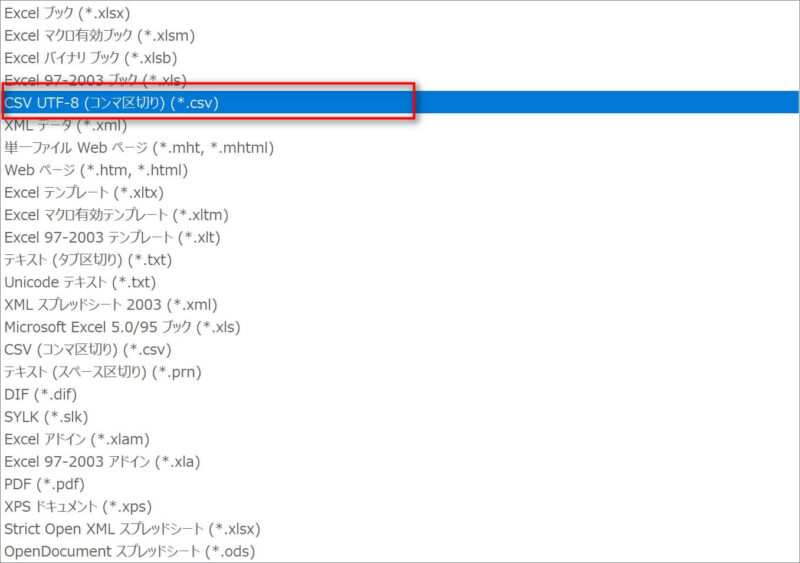
Python側のコードで指定できるのかもしれないが、今回は元データを修正したことで無理やり解決、ということにした。
単語単位で分割
いよいよPythonのお出ましである。が、根本的な壁にぶつかる。
ファイルはどこに保管すべきで、どこに保存されるのか
そもそも作成したcsvをどこに保管したらいいか知らない。フォントもどうやって指定できるのか不明だ。あまつさえ、WordCloudで作成された画像がどこに保存されるかも分からない。
という状態なので、ChatGPT先生に全部訊くことにした。
何度訊こうとも、質問がどれだけ初歩的な内容でも、一切怒らずに全部教えてくれるのでうれしい。
ChatGPTに訊いた内容
Pythonでやりたいことを整理したうえでプロンプトを実行したところ、以下の回答を得た。回答を丸写しして作成したコードは以下のとおりである。
# 必要なライブラリのインストール
!pip install janome
!pip install wordcloud
!pip install matplotlib
!pip install pandas
# ライブラリのインポート
import pandas as pd
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from IPython.display import Image
import numpy as np
from PIL import Image
# Googleドライブとの連携
from google.colab import drive
drive.mount('/content/drive')
# CSVファイルを読み込む(ファイルパスは適切に変更してください)
csv_path = '/content/drive/MyDrive/フォルダ名/csvファイル名'
df = pd.read_csv(csv_path)
# 形態素解析の関数
def analyze_reviews(text):
t = Tokenizer()
tokens = t.tokenize(text)
exclusion_pos = ['助詞', '助動詞']
return [token.base_form for token in tokens
if token.part_of_speech.split(',')[0]not in exclusion_pos]
# 歌詞データに対して形態素解析を適用
df['analyzed_reviews'] = df['歌詞'].apply(analyze_reviews)
# 解析結果を空白で結合
text_for_wordcloud = ' '.join(df['analyzed_reviews'].explode().dropna())
# 削除するワードをリスト化(任意のワードを提示してください)
stopwords = ['ん','さ', 'よう', 'の', 'こと', 'する', 'そう', 'てる','れる','なる','いる','あの','この','その','ある','ない','く','まま']
# WordCloudの生成
wordcloud = WordCloud(font_path='/content/drive/MyDrive/フォント用フォルダ名/フォント名',
width=1200, height=720,
background_color='white',
contour_color='#131313', # 輪郭色
colormap='bone',
contour_width=2,
collocations=False, # 重複した単語の表示を無効化
stopwords=set(stopwords)).generate(text_for_wordcloud)
# WordCloudの表示
plt.figure(figsize=(12, 7.2))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
# WordCloudの画像を保存
output_image_path = '/content/drive/MyDrive/wordcloud_image.png'
wordcloud.to_file(output_image_path)
# 保存された画像の表示
Image.open(output_image_path)
なお、上記のコードは質問を重ねたことで得た最終版である。ChatGPTといえども、必ずしも100%正確な回答を提示してくれるわけではないことは銘記すべきである。
人間であればなんとなく意図を察して返答したり、代替案を提案してくれたりもする。しかし、ChatGPTがどれだけ優秀であろうとも、今のところAIが気を遣ったり、相手の顔色を窺うことはない。このことを念頭に置いて質問を投げかけることが重要である。
単語を可視化
試行錯誤(をしたのはChatGPTとも言えるかもしれないが)の結果、WordCloudで可視化できたのは以下の画像である。
一言で言って、滾る…。滾らずにはいられない。だって、そこに広がるのは、まぎれもなくTHE BACK HORNの凝縮だからだ。
彼らの歌詞データをもとに頻出ワードを出力したのだから、そんなの当然の結果なのだが、改めてTHE BACK HORNの言葉を切り分けて見ることが叶ったのは、最高にうれしいことである。

以下、ChatGPTからコードを取得するにあたり、盛り込みたかった点は以下の3つである。
- 可視化する単語の選定
- 使用するフォント
- 文字の色
可視化する単語の選定
除外するワードはできるだけ最小限に留めたいのが本音だが、意味を掴み切れない語が入るのは不本意である。
そのため、可視化する品詞は「助詞と助動詞以外のすべて」としたうえで、以下の語を削除することにした。
stopwords = ['ん','さ', 'よう', 'の', 'こと', 'する', 'そう', 'てる','れる','なる','いる','あの','この','その','ある','ない','く','まま']若干多くなってしまったように思うのだが、結果的に噛み砕くことができる単語が残ってくれたので、恣意的な意図がないとは言えないが、それでも、悪くないと、言いたい…。
使用するフォント
本来は、PC内にインストールされているフォントを用いて出力できるらしい。が、今回は、歌詞データのcsvファイル同様に、Googleドライブの任意のフォルダに使いたいフォントをアップロードし、Pythonで指定することにした。
THE BACK HORNの言葉を可視化するなら、ゴシックよりも明朝体が好い…という個人的な願望により、今回は「しっぽり明朝」を使用することに。結果、好い。すごく好い。語が切れ切れになるくらいによかった。
文字の色
WordCloudでは、「matplotlib」というライブラリ内にあるカラーマップから色調を指定することができる。ここにあるパターンだけでも十分に応用が利く。
とはいえ、こちとら如何せん強欲なオタクである。満足することを知らない。
ここまでTHE BACK HORNに寄せたのだから、色合いもTHE BACK HORNぽくしたい!と思うのが強欲なオタクが思うことである。
WordCloudは画像の情報から色を取得してくれるらしいので、せっかくならばTHE BACK HORNのジャケットを読み込ませて、文字色を反映させたい。
そう思って(ChatGPTが)試行錯誤した結果出来上がったのが、上記の画像である。このコードは次回の記事で紹介することにする。同じ要領でamazarashiの歌詞分析も行ったので。
おわりに
ChatGPTさん、本当にありがとう、本当にすごいね…という気持ちはもちろんあるけれど、それよりも、何よりも主張したいのは、この言葉の羅列がとにもかくにもたまらねえ、ということである。
だって、改めてTHE BACK HORNの言葉に改めてふれることができたのだ。こんなにもうれしいことはない。世に放たれた楽曲たちが積み重ねた言葉が、ここに集積している。それを目の当たりにできたことは、代えがたい喜びである。
ミリしらでも目的を達成できた、その事実が、正直、ものすごくうれしい。
99%をChatGPTにやってもらったのに、現金なものである。
冒頭でもふれたとおり、今回の目的は、あくまでも取得した歌詞データを単語単位で切り分け、頻出ワードを可視化する、ということであり、プログラミングの知識を身に着けることではなかった。
そういう意味では、達成感を覚えてもおかしくはない。これはこれで、おもしろい遊びができた、と思っている。
とはいえ、気にかかることも、もちろんある。
例えば、ChatGPTは理想を実現するための一助であり、最適解を提案するわけではないこと、自らが学ぼうとしない限りは、知識として蓄積されないこと、などである。
前者に関して言えば、WordCloudで可視化するにあって、私には明確にやりたいことがあった。フォントはこれを使って、色はこの画像を用いて、除外するワードはこれで…など、具体的にイメージができていた。
でもそれは、様々なページを見て、「WordCloudでどういうことができるのか」をあらかじめ情報収集していたからである。
だから、ChatGPTにも、WordCloudでできることを踏まえたうえで、あれこれしたい、こうしたい、など、重ね重ね要望を伝えた。
それにより、最終的に理想とするコードの取得に至った。が、ChatGPTが「こういうこともできるよ!」と知らない情報を教えてくれたわけではない。あくまでも、教えてほしいこと以外は教えてくれない。教えてほしいこと以外は訊いていないのだから、当たり前である。
そう思うと、先人が積み重ねた叡智の尊さを噛み締めずにはいられない。そうした情報があったからこそ、私は目的地に到達できたのだ。
今回の経験を機に、改めてプログラミングやPythonを学ぶ気になったかというと、やはりそれも別だ。WordCloudでの可視化はものすごくおもしろかった。とはいえ、取り組もうと思えたのは、好きなバンドの歌詞分析をやりたい、という希望があってのことである。
今回私が行ったことを端的に言えば、ChatGPTへの質問と、そこから得たコードをPythonに切り貼りした、という動きのみである。これでは能力として身につくわけもない。
自分が設定した目的に応じて、ChatGPTをはじめとした利器を文字通り使う必要がある。あくまでも、主導権は人間にあるのだから。
気が向いたらまた遊んでみようと思う。


コメント